Introduction
This document assumes the knowledge of the W3C recommendation
or working drafts used in Cocoon (mainly XML,
XSL in both its transformation
and formatting capabilities). This
document is not intended to be an XML or XSL tutorial but just shows how these
technologies may be used inside the Cocoon framework to create web content.
General overview
Cocoon is a publishing system that allows you to separate web development into
three different layers: content, style and logic.
In a way, Cocoon does not aim to simplify the creation of web content:
in fact, it is harder to create XML/XSL content than it is to use HTML from
the beginning. So, if you
are happy with the web technology you are using today, don't waste your time
and stick with what you already have. Otherwise, if your troubles are site
management, if your graphics people are always in the way, if your HTML authors
always mess up your page logic, if your managers see no results in hiring new
people to work on the site - go on and make your life easier!
This comment posted on the Cocoon mailing list shows you what we mean:
 | | | |
I've got a site up and running that uses Cocoon.
It rocks, the management loves me (they now treat
me like I walk on water), and a couple of summer
interns that I had helping me on the project are
suddenly getting massively head-hunted by companies
like AT&T now that they can put XML and XSL on
their resumes. In a word: Cocoon simply rocks!
| | | | |
Every good user guide starts with a Hello World example,
and since we hope to write good documentation (even if it's as hard as hell!),
we'll start from there too. Here is a well-formed XML file that uses a custom
and simple set of tags:
| | | |
<?xml version="1.0"?>
<page>
<title>Hello World!</title>
<content>
<paragraph>This is my first Cocoon page!</paragraph>
</content>
</page>
| | | | |
Even if this page mimics HTML (in a sense, HTML was born as a simple DTD
for homepages), it is helpful to note that there is no style information
and all the styling and graphic part is missing. Where do I put the title? How
do I format the paragraph? How do I separated the content from the other
elements? All these questions do not have answers because in this context they
don't need one: this file should be created and maintained by people that
don't need to be aware of how this content if further processed to become a
served web document.
On the other hand, we need to indicate how the presentation questions will
be answered. To do this, we must indicate a stylesheet that is able to
indicate how to interpret the elements found in this document. Thus, we
follow a W3C recommendation
and add the XML processing instruction to map a stylesheet to a document:
| | | | <?xml-stylesheet href="hello.xsl" type="text/xsl"?> | | | | |
Now that our content layer is done, we need to create a stylesheet to
convert it to a format readable by our web clients. Since most available web
clients use HTML as their lingua franca, we'll write a stylesheet to
convert our XML in HTML (More precisely, we convert to XHTML which is the XML
form of HTML, but we don't need to be that precise at this point).
Every valid stylesheet must start with the root element stylesheet
and define its own namespace according to the W3C directions. So the
skeleton of your stylesheet is:
| | | |
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
</xsl:stylesheet>
| | | | |
Once the skeleton is done, you must include your template elements,
which are the basic units of operation for the XSLT language. Each template is
matched against the occurence of some elements in the original document and
the element is replaced with the child elements of the template,
if they belong to other namespaces, or, if they belong to the XSLT namespace,
they are further processed in a recursive way.
Let's see an example: in our HelloWorld.xml document
page is the root element. This must be transformed into all those tags
that identify a good HTML page. Your template becomes:
| | | |
<xsl:template match="page">
<html>
<head>
<title><xsl:value-of select="title"/></title>
</head>
<body bgcolor="#ffffff">
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
| | | | |
where some elements belong to the standard namespace (which we mentally
associate with HTML) and some others to the xsl: namespace.
Here we find two of those
XSLT elements: value-of and apply-templates. While
the first searches the page element's direct children for the
title element and
replaces it with the content of the retrieved element, the second indicates
to the processor that it should continue the processing of the other templates
described in the stylesheet from that point on in the input document
(known as the context node).
Some other possible templates are:
| | | |
<xsl:template match="title">
<h1 align="center">
<xsl:apply-templates/>
</h1>
</xsl:template>
<xsl:template match="paragraph">
<p align="center">
<i><xsl:apply-templates/></i>
</p>
</xsl:template>
| | | | |
After the XSLT processing, the original document is transformed to
| | | |
<html>
<head>
<title>Hello</title>
</head>
<body bgcolor="#ffffff">
<h1 align="center">Hello</h1>
<p align="center">
<i>This is my first Cocoon page!</i>
</p>
</body>
</html>
| | | | |
When a document is processed by an XSLT processor, its output is exactly the same for every browser that requested
the page. Sometimes it's very helpful to be able to discover the client's
capabilities and transform content layer into different views/formats. This is
extremely useful when we want to serve content do very different types of
clients (fat clients like desktop workstations and thin clients like wireless
PDAs), but we want to use the same information source and create the smallest
possible impact on the site management costs.
Cocoon is able to discriminate between browsers, allowing the different stylesheets to
be applied. This is done by indicating in the stylesheet linking PI the media
type. For example, continuing with the HelloWorld.xml document, these PIs
| | | |
<?xml version="1.0"?>
<?xml-stylesheet href="hello.xsl" type="text/xsl"?>
<?xml-stylesheet href="hello-text.xsl" type="text/xsl" media="lynx"?>
...
| | | | |
would tell Cocoon to apply the hello-text.xsl stylesheet if the Lynx browser
is requesting the page. This powerful feature allows you to design your content
independently and to choose its presentation depending on the capabilities of the browser
agent.
The media type of each browser is evaluated by Cocoon at request time,
based on their User-Agent http header information.
Cocoon is preconfigured to handle these browsers:
explorer -
any Microsoft Internet Explorer, searches for MSIE (before
searching for Mozilla, since IE pretends to be Mozilla too)
opera -
the Opera browser (before searching for Mozilla, since
Opera pretends to be Mozilla too)
lynx -
the text-only Lynx browser
java -
any Java code using standard URL classes
wap -
the Nokia WAP Toolkit browser
netscape -
any Netscape Navigator or Mozilla, searches for Mozilla
but you can add your own by personalizing the
cocoon.properties file, modifying the browser
properties. For example:
| | | |
browser.0=explorer=MSIE
browser.1=opera=Opera
browser.2=lynx=Lynx
browser.3=java=Java
browser.4=wap=Nokia-WAP-Toolkit
browser.5=netscape=Mozilla
| | | | |
indicates that Cocoon should look for the token MSIE inside the
User-Agent HTTP request header first, then Opera
and so on, until Mozilla.
If you want to recognize different generations of the same browser you should
find the specific string you should look for, and
- this is very important - indicate the order of matching, since
other browsers' User Agent strings may contain the same string
(see examples above).
Using query parameters during XSL transformation
Quite often you want to create pages that depend on some
user-supplied data. One way to do this is using HTML forms.
Cocoon provides you with a simple way to use this data. Let's
assume you've got the following list and you want the user
to choose a country code and be shown the name of the corresponding
country.
| | | |
<?xml version="1.0"?>
<?cocoon-process type="xslt"?>
<?xml-stylesheet href="page.xsl" type="text/xsl"?>
<page>
<country code="ca">Canada</country>
<country code="de">Germany</country>
<country code="fr">France</country>
<country code="uk">United Kingdom</country>
<country code="us">United States</country>
<country code="es">Spain</country>
</page>
| | | | |
You now use the following XSL stylesheet with it
| | | |
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:param name="countrycode"/>
<xsl:template match="page">
<html>
<body>
<xsl:choose>
<xsl:when test="not($countrycode)">
<p>Choose a country:</p>
<form action="countries.xml" method="get">
<select name="countrycode" size="1">
<xsl:apply-templates select="country" mode="form"/>
</select>
<input type="submit"/>
</form>
</xsl:when>
<xsl:when test="country[@code=$countrycode]">
<xsl:apply-templates select="country[@code=$countrycode]"
mode="selected"/>
</xsl:when>
<xsl:otherwise>
<p>Unknown country code
<em><xsl:value-of select="$countrycode"/></em>.
</p>
</xsl:otherwise>
</xsl:choose>
</body>
</html>
</xsl:template>
<xsl:template match="country" mode="form">
<option><xsl:value-of select="@code"/></option>
</xsl:template>
<xsl:template match="country" mode="selected">
<p><em><xsl:value-of select="@code"/></em> stands for
<xsl:value-of select="text()"/></p>
</xsl:template>
</xsl:stylesheet>
| | | | |
Viewing countries.xml now will yield different
results. When no parameter is given (i.e. using the URL
countries.xml) the browser will receive the following page:
| | | |
<html>
<body>
<p>Choose a country:</p>
<form action="countries.xml" method="get">
<select name="countrycode" size="1">
<option>ca</option>
<option>de</option>
<option>fr</option>
<option>uk</option>
<option>us</option>
<option>es</option>
</select>
<input type="submit">
</form>
</body>
</html>
| | | | |
Choosing one of the options in the list will result in a request
for a URL like countries.xml?countrycode=fr and this page
will look like:
| | | |
<html>
<body>
<p><em>fr</em> stands for France</p>
</body>
</html>
| | | | |
If for some reason no country element matching the
countrycode parameter is found (e.g.
countries.xml?countrycode=foo, you will get the following
page:
| | | |
<html>
<body>
<p>Unknown country code <em>foo</em>.</p>
</body>
</html>
| | | | |
The Cocoon publishing system has an engine based on the reactor design
pattern which is described in the picture below:
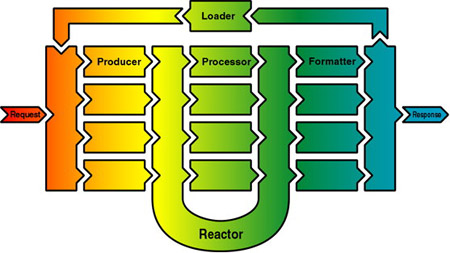
Let's describe the components that appear on the schema:
Request -
Wraps around the client's request and
contains all the information needed by the processing engine. The request
must indicate which client generated the request, which URI is being
requested and which producer should handle the request.
Producer -
Handles the requested URI and produces an
XML document. Since producers are pluggable, they work like subservlets
for this framework, allowing users to define and implement their own
producers. A producer is responsible for creating the XML document which is
fed into the processing reactor. It's up to the producer implementation to
define the function that produces the document from the request object.
Reactor -
Responsible for evaluating which processor should work on the document by
reacting on XML processing
instructions. The reactor pattern is different from a processing pipeline
since it allows the processing path to be dynamically configurable and it
increases performance since only those required processors are called to
handle the document. The reactor is also responsible for forwarding the
document to the appropriate formatter.
Formatter -
Transforms the memory representation of
the XML document into a stream that may be interpreted by the requesting
client. Depending on other processing instructions, the document leaves
the reactor and gets formatted for its consumer. The output MIME type of
the generated document depends on the formatter implementation.
Response -
Encapsulates the formatted document along
with its properties (such as length, MIME type, etc..)
Loader -
Responsible for loading the formatted
document when this is executable code. This part is used for compiled
server pages (principally XSP) where the separation of content and logic
is merged and
compiled into a Producer. When the formatter output is executable code, it
is not sent back to the client directly, but it gets loaded and executed
as a document producer. This guarantees both performance improvement
(since the producers are cached) as well as easier producer development,
following the common compiled server pages model.
Cocoon Processing Instructions
The Cocoon reactor uses XML processing instructions to forward the document
to the right processor or formatter. These processing instructions are:
| | | |
<?cocoon-process type="xxx"?> for processing
and
<?cocoon-format type="yyy"?> for formatting
| | | | |
These PIs are used to indicate the processing and formatting path that the
document should follow to be served. In the example above, we didn't use them
and Cocoon wouldn't know (despite the presence of the XSL PIs) that the
document should be processed by the XSLT processor. To do this, the HelloWorld.xml
document should be modified like this:
| | | |
<?xml version="1.0"?>
<?cocoon-process type="xslt"?>
<?xml-stylesheet href="hello.xsl" type="text/xsl"?>
<page>
<title>Hello World!</title>
<content>
<paragraph>This is my first Cocoon page!</paragraph>
</content>
</page>
| | | | |
The other processing instruction is used to indicate what formatter should
be used to transform the document tree into a suitable form for the requesting
client. For example, in the document below that uses the XSL formatting object
namespace, the Cocoon PI indicates that this document should be formatted using the
formatter associated to the text/xslfo document type.
| | | |
<?xml version="1.0"?>
<?cocoon-format type="text/xslfo"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<fo:layout-master-set>
<fo:simple-page-master
page-master-name="one"
margin-left="100pt"
margin-right="100pt">
<fo:region-body margin-top="50pt"
margin-bottom="50pt"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence>
<fo:sequence-specification>
<fo:sequence-specifier-repeating
page-master-first="one"
page-master-repeating="one"/>
</fo:sequence-specification>
<fo:flow font-size="14pt" line-height="14pt">
<fo:block>Welcome to Cocoon</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
| | | | |
In a complex server environment like Cocoon, performance and
memory usage are critical issues. Moreover, the processing requirement for
both XML parsing, XSLT transformations, document processing and formatting are
too heavy even for the lightest serving environment based on the fastest
virtual machine. For this reason, a special cache system was designed underneath the Cocoon
engine and its able to cache both static and dynamically created pages.
Its operation is simple but rather powerful:
- when the request comes, the cache is searched.
- if the request is found;
- its changeable points are evaluated
- if all changeable points are unchanged
- the page is served directly from the cache
- if a single point has changed and requires reprocessing
- the page is invalidated and continues as if it wasn't found
- if the request is not found:
- the page is normally processed
- it's sent to the client
- it's stored into the cache
This special cache system is required since the page is
processed with the help of many components which, independently, may change
over time. For example, a stylesheet or a file template may be updated on
disk. Every processing logic that may change its behavior over time it's
considered changeable and checked at request time for change.
Each changeable point is queried at request time and it's up
to the implementation to provide a fast method to check if the stored page is
still valid. This allows even dynamically generated pages (for example,
an XML template page created by querying a database) to be cached and,
assuming that request frequency is higher than the resource changes, it
greatly reduces the total server load.
Moreover, the cache system includes a persistent object
storage system which is able to save stored objects in a persistent state that
outlives the JVM execution. This is mainly used for pages that are very
expensive to generate and last very long without changes, such as compiled
server pages.
The store system is responsible for handling the cached pages
as well as the pre-parsed XML documents. This is mostly used by XSLT
processors which store their stylesheets in a pre-parsed form to speed up
execution in those cases where the original file has changed, but the
stylesheet has not (which is a rather frequent case).
|